The range class is the heart of table scripting support in Numbers. This class contains the essential style and format properties inherited and shared by cells, rows, and columns.
range n : A range of cells in a table
elements
contains cells, columns, rows; contained by tables.
properties
alignment ( auto align/center/justify/left/right ) : The horizontal alignment of content in the range’s cells.
background color ( color ) : The background color of the range’s cells. Expressed as a list of RGB (Red, Green, Blue) values, from 0 to 65535. For example, the color red is: {65535, 0, 0}
font name ( text ) : The font of the range’s cells. Can be the PostScript name (TimesNewRomanPS-ItalicMT), or the full name (Times New Roman Italic). TIP: Use the Font Book application to get the information about a typeface.
font size ( real ) : The font size (in points) of the range’s cells. ex: 12.5
format ( automatic/checkbox/currency/date and time/fraction/number/percent/pop up menu/scientific/slider/stepper/text/duration/rating/numeral system ) : The cell format of the range’s cells. Default format is automatic.
name ( text, r/o ) : The range’s coordinates. A text string expressed as colon-delimited cell IDs. ex: "A2:F6"
text color ( color ) : The text color of the range’s cells. Expressed as a list of RGB (Red, Green, Blue) values, from 0 to 65535. For example, the color yellow is: {65535, 65535, 0}
text wrap ( boolean ) : Whether text should wrap in the range’s cells.
vertical alignment ( bottom/center/top ) : The vertical alignment of content in the range’s cells.
responds to
clear, add column after, add column before, add row above, add row below, merge, unmerge.
In Numbers, and in Numbers scripting, ranges are a collection of contiguous cells. Cells are referenced in scripts by their index or by name.
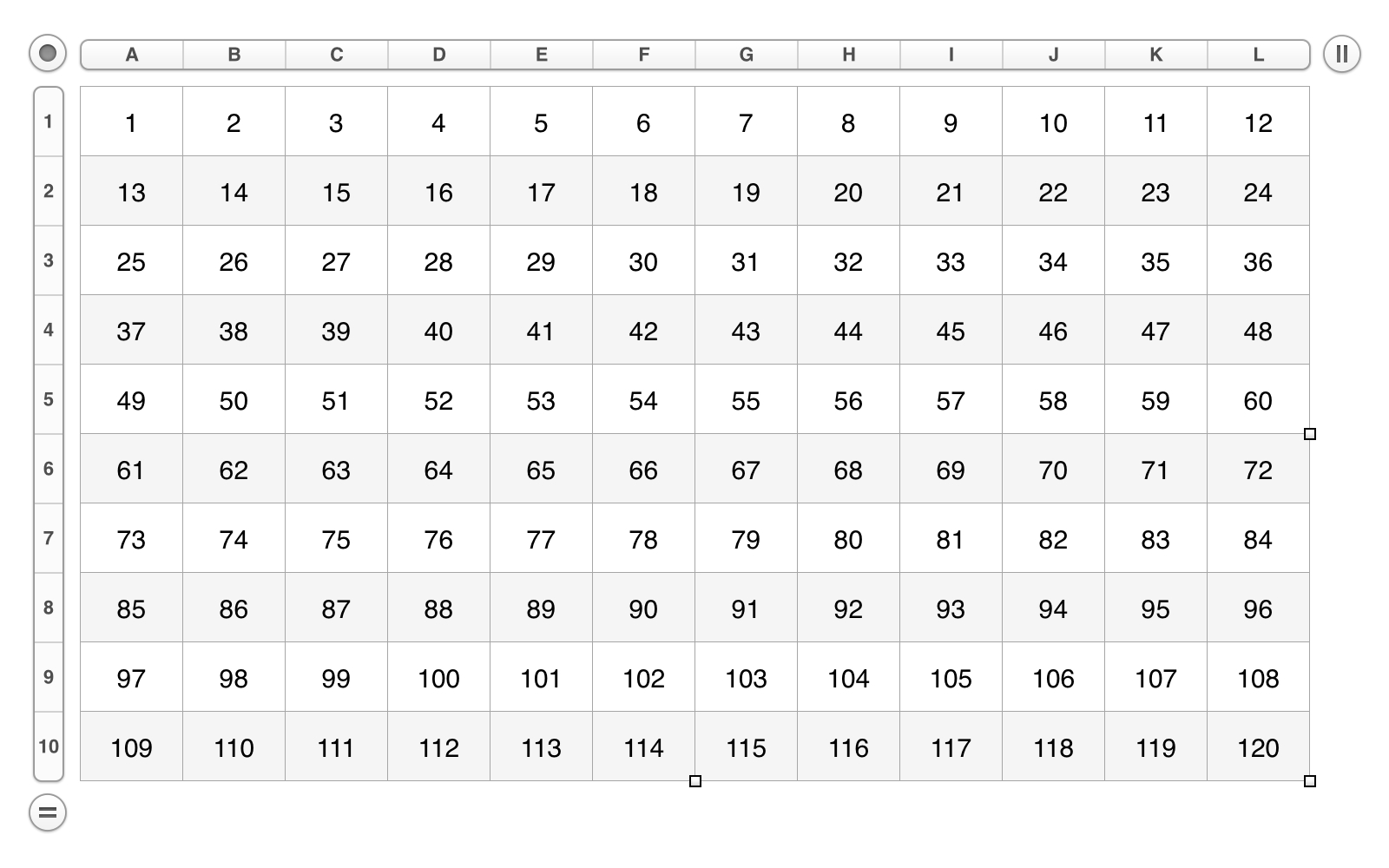
A cell’s index is an integer value, indicating the cell’s order in all of the cells of the table. The following script will create a table where the value of each cell will be the cell’s index in the table.
The result of the script execution will be a table similar to the one below. Note that cell indexes are determined by rows, from left of the table to the right of the table, and from the top of the table to the bottom of the table. Also note, that cell indexes are only used as cell references by scripts, not by the application interface.
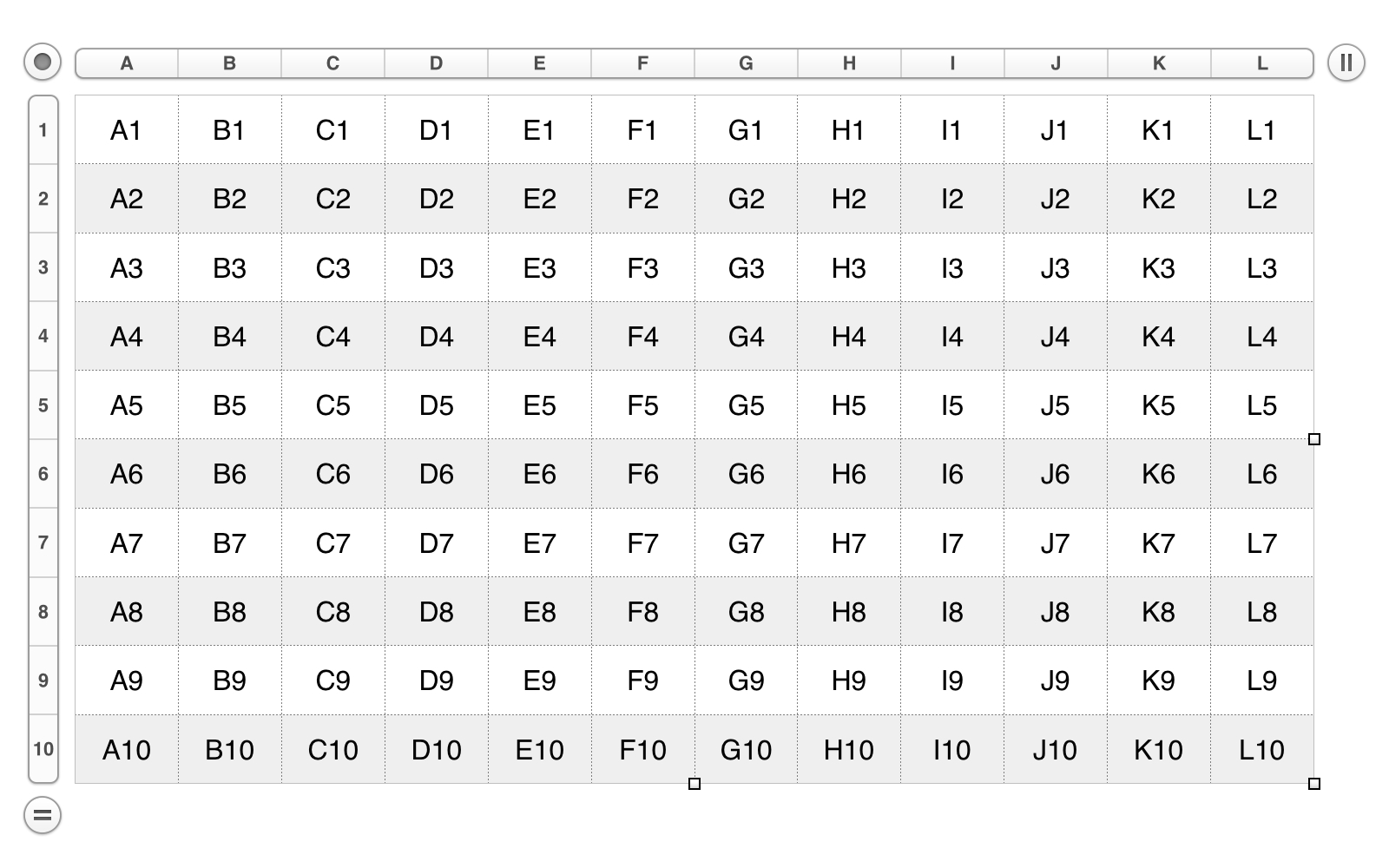
A cell’s name is a text string indicating its position in the cells of its parent column. A cell name is also referred to as its address. The following script will create a table where the value of each cell will be the cell’s name (address).
The result of the script execution will be a table similar to the one below. Note that cell indexes are determined by columns, from left of the table to the right of the table, and from the top of the table to the bottom of the table. Also note, that cell names are used as cell references by scripts, and by the application interface.